Reviewing data science projects can be overwhelming, but a structured approach ensures quality and reliability. Here's a quick guide to get started:
- Set Clear Goals: Define problem statements, align with stakeholders, and establish measurable success metrics.
- Check Data Quality: Validate data sources, clean datasets, and ensure consistency.
- Model Development: Choose the right algorithms, select features carefully, and test thoroughly.
- Review Results: Ensure clarity in findings, use quality visualizations, and validate statistical methods.
- Organize Project Structure: Maintain clear documentation, follow version control best practices, and manage dependencies effectively.
- Use Tools: Leverage review tools like GitNotebooks for efficient collaboration and feedback.
Quick Overview of Key Areas
| Area | Focus | Why It Matters |
|---|---|---|
| Goals | Problem clarity, success metrics | Aligns efforts with business needs |
| Data Quality | Validation, cleaning | Avoids errors in analysis |
| Model Development | Feature and algorithm selection | Ensures accuracy and reliability |
| Results | Clarity, graphs, statistical soundness | Communicates impact effectively |
| Structure | Documentation, version control | Improves collaboration and reproducibility |
| Tools | Review platforms | Speeds up feedback and iteration |
Related video from YouTube
::: @iframe https://www.youtube.com/embed/lia4oIOPcG4 :::
1. Set Project Goals and Metrics
Establish clear goals and measurable metrics to ensure your technical efforts align with business priorities.
Problem Statement Review
A well-defined problem statement keeps the project on track. Assess it for clarity, scope, business relevance, and alignment with stakeholders.
| Criteria | Description | Example Check |
|---|---|---|
| Clarity | Simple explanation, free of jargon | Can non-technical stakeholders follow it? |
| Scope | Clearly outlines boundaries and limits | Are constraints and exclusions defined? |
| Business Impact | Directly tied to business goals | Does it address a pressing business need? |
| Stakeholder Alignment | Consensus across involved teams | Do all key stakeholders agree on it? |
"A problem statement is a clear and concise description of the issue you aim to solve using data science. It serves as a guiding framework that defines the project's scope, objectives, and constraints." – Mohamed Chizari, Data Scientist [3]
Once the problem is clear, translate it into actionable success metrics.
"Communicating clearly and frequently with cross-functional stakeholders is crucial for any data science team. When it comes to non-technical stakeholders, it's essential to provide the context and the 'why' behind projects so they can understand the significance of the work being done." [4]
Success Metrics Review
Define three types of metrics to track progress and impact:
- Leading Metrics: These help predict outcomes. For example, monitor total prospect opportunities, deal closure probabilities, or opportunity values.
- Lagging Metrics: These are quantifiable, time-specific, and directly tied to objectives. Regularly review them to assess results.
- Usage/Health Metrics: Focus on how the solution performs in practice. Examples include model usage frequency, user satisfaction scores, feedback from implementation, and system performance data.
"Data Scientists need to get better at marketing their own success inside organizations. One of the key elements of showcasing these successes is setting clear expectations with stakeholders during any project initiation phase." – David Bloch [2]
Use the SMART framework (Specific, Measurable, Achievable, Relevant, Time-bound) [1] to create benchmarks that make success easy to evaluate.
2. Check Data Quality
Ensuring high-quality data is crucial for the success of any data science project. Start by assessing the reliability of your data sources and the thoroughness of your cleaning processes. Poor-quality data can be costly - organizations lose an average of $15 million annually because of it [7]. That's why quality checks are non-negotiable.
Data Source Review
Reliable data sources are the backbone of any data-driven initiative. According to a 2024 report, 92% of data leaders say data reliability is central to their strategies. Yet, 68% of data teams admit they lack full confidence in the quality of data used for their AI applications [5].
| Verification Area | Key Checks | Success Criteria |
|---|---|---|
| Source Reliability | Data consistency, update frequency | Source is validated |
| Access Control | Authentication methods, permissions | Role-based access is in place |
| Data Lineage | Tracking origins, transformation history | Complete audit trail exists |
| Documentation | Metadata management, source details | Documentation is up to date |
Here’s what you should do:
- Develop a clear data governance framework. Define standardized practices for collecting data, identify acceptable sources, and set up validation procedures.
- Ensure your systems can handle real-time updates without compromising data integrity.
- Apply strict validation protocols when working with third-party data.
Data Cleaning Review
Cleaning data is a time-consuming but essential task - data scientists spend over 80% of their time on it [7]. Proper cleaning ensures your models receive reliable inputs, leading to more accurate results.
A great example comes from March 2023, when Mailchimp's client Spotify improved email deliverability. By reducing bounce rates from 12.3% to 2.1%, they boosted deliverability by 34%, resulting in $2.3 million in additional revenue [6].
Focus on these areas during data cleaning:
| Cleaning Task | Method | Tools |
|---|---|---|
| Missing Values | Imputation, deletion, or adding a "missing" category | Functions like isnull() and dropna() in Pandas |
| Duplicates | Identify and remove | Automated deduplication tools |
| Outliers | Detect and address | Use Z-scores or scatter plots |
| Format Standardization | Ensure consistency in dates, currencies, and text | Custom validation scripts |
Check for correct data types, fix structural errors (like typos or inconsistent capitalization), and monitor quality metrics to measure improvements.
To streamline this process, set up automated pipelines for continuous quality checks. Be sure to document every transformation and quality improvement step [8].
Next, move on to reviewing the criteria for model development.
3. Check Model Development
After preparing your data, the next step is model development. This phase is critical for determining the success of your project. It involves reviewing model selection, feature selection, and testing to ensure reliable outcomes.
Model Selection Review
Choose models that fit the problem, the data, and the specific business needs. Ensure the algorithms you pick align with these factors.
| Model Type | Best Use Cases | Key Considerations |
|---|---|---|
| Linear Models | Simple relationships, small datasets | Quick to train, easy to interpret |
| Tree-based Models | Non-linear data, high dimensionality | Handle missing values effectively |
| Neural Networks | Complex patterns, large datasets | Require significant computing power |
| Ensemble Methods | Production environments | Balance between accuracy and complexity |
Feature Selection Review
Choosing the wrong features can lead to bias or overfitting.
"Machine learning models work on the principle of 'Garbage In Garbage Out,' which means if you provide poor quality, noisy data, the results produced by ML models will also be poor." - Andrew Tate [10]
Research highlights how improper feature selection can skew results [9]:
| Metric | Potential Bias |
|---|---|
| AUC-ROC | Up to 0.15 |
| AUC-F1 | Up to 0.29 |
| Accuracy | Up to 0.17 |
To avoid these pitfalls, follow these steps:
- Document selection criteria: Clearly note why each feature was included or excluded.
- Check for multicollinearity: Look for features that are highly correlated and address them.
- Validate feature importance rankings: Use multiple methods to confirm the relevance of selected features.
Once you're confident in your features and model choice, move on to testing.
Model Testing Review
"Evaluating model performance is a critical step in the data analytics and machine learning pipeline. It helps us understand how well our models are performing, identify areas for improvement, and make informed decisions." - Zhong Hong, Data Analyst [11]
When reviewing model testing, consider the following:
| Testing Aspect | Review Points | Success Criteria |
|---|---|---|
| Baseline Comparison | Compare performance to simple models | Demonstrates clear improvement |
| Cross-validation | Review K-fold validation results | Consistent performance across folds |
| Metric Selection | Match metrics to the problem | Metrics align with business goals |
| Error Analysis | Look for patterns in errors | Avoid systematic mistakes |
For classification problems, prioritize metrics like precision, recall, and F1-score. For regression tasks, focus on MAE or RMSE measurements [12].
It's also essential to monitor models in production. Set up automated testing pipelines to catch performance drops and ensure accuracy remains above acceptable thresholds [12].
sbb-itb-6b675b7
4. Review Results and Graphs
This step ensures your findings meet the project's quality standards and are communicated effectively. After confirming your model's performance, it's time to focus on presenting your results in a way that's clear and impactful. Here's how to review the clarity of your findings, the quality of your graphs, and the validity of your statistical methods.
Results Clarity Check
Your results should be easy for stakeholders to understand without losing technical accuracy. Use the table below to guide your review:
| Clarity Aspect | Review Questions | Success Criteria |
|---|---|---|
| Context | Is background information provided? | Readers understand why results matter |
| Benefits | Are advantages clearly stated? | Impact is quantified where possible |
| Limitations | Are constraints documented? | Assumptions and scope are clear |
| Actions | Are next steps outlined? | Recommendations are specific and actionable |
"Cairo emphasizes that confusing or misleading visuals, even unintentionally, are unethical as they hinder understanding. The visuals should maximize the good outcomes and contribute to personal well-being through transparent and effective data communication." [13]
Once your results are clear, turn your attention to the quality of your visualizations.
Graph Quality Check
Well-crafted graphs make your data easier to interpret. Use this checklist to evaluate your visualizations:
- Graph Selection: Pick the right chart type for your data.
- Axis Configuration: Clearly label axes, including units and scales.
- Data Representation: Ensure data points are plotted accurately.
- Visual Accessibility: Use appropriate contrast and colors for readability.
Be mindful of common mistakes like:
- Misleading scales that distort relationships.
- Cherry-picked data that misrepresents the findings.
- Ambiguous labels that confuse the audience.
- Missing context that leads to misinterpretation.
Statistical Review
Once your visuals are polished, verify the statistical soundness of your findings. This table outlines key areas to focus on:
| Validation Aspect | Key Considerations | Validation Method |
|---|---|---|
| Model Assumptions | Do statistical assumptions hold? | Residual analysis |
| Data Distribution | Are probability distributions appropriate? | Distribution tests |
| Prediction Accuracy | How reliable are forecasts? | Cross-validation |
| Error Analysis | Are systematic errors addressed? | Expert review |
When performing a statistical review, keep these tips in mind:
- Double-check that your model assumptions are valid.
- Clearly document your methodology.
- Include confidence intervals to show result reliability.
- Be transparent about any limitations.
As noted in research [14], there’s no one-size-fits-all approach to statistical validation. Your methods should align with the specific goals and design of your project.
5. Check Project Structure
After verifying your results, it's time to organize your project. A clear structure makes collaboration easier and ensures your work can be reproduced efficiently.
Code Structure Review
How you organize your project directly affects how others (and your future self) can navigate and understand it. Here's a practical breakdown:
| Component | Purpose | Key Requirements |
|---|---|---|
| README.md | Project documentation | Include an overview, setup steps, and usage instructions |
| src/ folder | Source code | Group by programming language (e.g., Python, R, Stata) |
| data/ folder | Project data | Keep raw and processed data separate |
| output/ folder | Generated files | Store results, graphs, and reports |
| docs/ folder | Documentation | Provide additional technical details |
For consistency, use kebab-case for project names and format date-based files as YYYY-MM-DD for better sorting and clarity.
"One key to open reproducible science is to provide rigorous organization of all project material. Not just for someone else to use, but also for you, if and when you return to the project after some time and/or when the project complexity increases." - calekochenour, project-structure GitHub repository
A well-structured codebase also lays the groundwork for effective version control.
Version Control Check
Version control is essential for tracking changes and collaborating with others. Here's what to review:
- Track all code files in Git to ensure nothing important is missed.
- Use a .gitignore file to exclude large data files or sensitive information.
- Write clear and descriptive commit messages to document changes effectively.
- Follow your team's branching conventions for better collaboration.
As Max Masnick aptly puts it, "Code does not exist unless it is version controlled."
At the same time, managing dependencies is just as critical for ensuring reproducibility.
Package Management Review
Handling dependencies properly guarantees that your project can be recreated by others without issues. Focus on these key elements:
| Requirement | Implementation | Purpose |
|---|---|---|
| Virtual Environment | Use tools like environment.yml or venv | Keep project dependencies isolated |
| Requirements File | Create a requirements.txt file | List all package versions explicitly |
| Installation Guide | Provide setup instructions | Make it easy for others to replicate your environment |
For Python projects, run pip freeze > requirements.txt to capture exact package versions. This allows others to recreate your environment with pip install -r requirements.txt.
"It is the first file a person will see when they encounter your project, so it should be fairly brief but detailed." - Hillary Nyakundi [15]
6. Review Tools and Software
Efficiently reviewing data science projects requires tools designed to simplify the process and improve team collaboration.
GitNotebooks Features
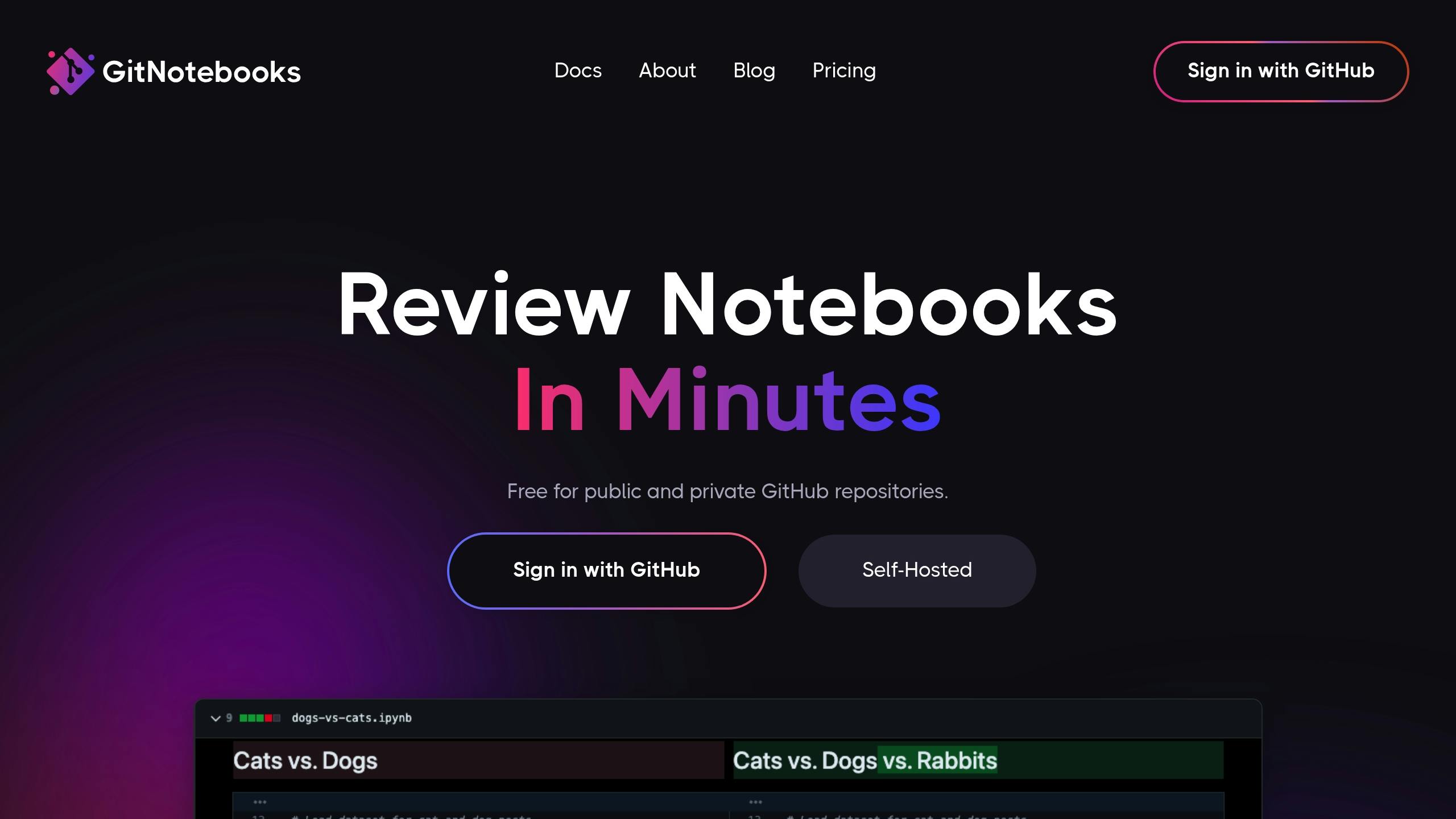
GitNotebooks makes reviewing Jupyter Notebooks easier by addressing common challenges with the following features:
| Feature Category | Capabilities | Benefits |
|---|---|---|
| Rich Diffs | Code, markdown, dataframes, JSON, text, and images | Provides a clear view of all notebook changes |
| Security | Client-side code diffing | Ensures data privacy and protection |
| GitHub Integration | Automatic PR detection and commenting | Fits smoothly into existing workflows |
| Collaboration | Multi-line comments and code line wrapping | Enhances team communication and feedback |
These features highlight what you should look for in a review tool.
When choosing a review tool, focus on these key aspects:
- Comprehensive differencing for all notebook components
- Strong security measures to safeguard sensitive code
- Integration options to align with your current workflow
- Collaboration features that improve team interaction
GitNotebooks not only reduces review time but also enhances code quality, helping teams deliver analyses faster.
"With GitNotebooks our review time was cut in half, our team has accelerated analysis delivery, enhanced code quality, and reduced bottlenecks, allowing us to work more collaboratively and efficiently on analysis than ever before." [16]
"GitNotebooks has transformed how our data science team collaborates. With seamless GitHub integration, reviewing notebooks now mirrors code reviews for other files. With its intuitive UI, it feels natural and fits perfectly into our existing workflow. I recommend GitNotebooks to any data science team serious about their notebook quality." [16]
Pricing: Free for individuals or small teams (up to 12 users), $9.00 per user for teams, and custom plans for enterprise needs.
Incorporating tools like GitNotebooks ensures a consistent and efficient review process, maintaining high-quality standards and fostering better collaboration.
Conclusion
Checklist Overview
A thorough review process is key to delivering successful projects. Here's a quick breakdown of focus areas:
| Review Area | Key Focus Points | Why It Matters |
|---|---|---|
| Project Foundation | Clear problem statement, success metrics | Sets clear goals and measurable outcomes |
| Data Quality | Validating sources, cleaning data | Avoids issues in later analysis |
| Model Development | Feature selection, testing protocols | Ensures reliable and accurate models |
| Documentation | Organized code, version control | Streamlines knowledge sharing |
| Tools & Collaboration | Effective platforms, team workflows | Speeds up feedback and iteration |
Team Review Tips
To complement the checklist, consider these practical steps for better team collaboration:
- Hold regular review meetings to gather structured feedback.
- Standardize documentation practices for code, reports, and communication tools.
- Encourage constructive feedback that focuses on growth and improvement.
"Effective feedback in a data science team is as much an art as a science." - Eric J. Ma [18]
"Asking for feedback is a secretly powerful tool in data work." - Stephanie Kirmer [19]
Tailor the checklist to meet your organization's unique needs, while keeping it flexible enough to handle different project types [17]. These strategies can help refine your review process and push your projects toward success.